

В этой статье мы попытаемся дать ответ на главный вопрос — как создать современное аналитическое хранилище данных на базе экосистемы Cloudera на примере проекта, реализованного нами в “Газпромбанк” АО. Попутно расскажем как мы справились с основными вызовами при решении задачи.
“Газпромбанк” АО — один их ведущих системообразующих финансовых институтов РФ. Он входит в топ-3 банков по активам России и всей Восточной Европы и имеет разветвленную сеть дочерних филиалов.
Банк традиционно на рынке финансовых услуг был консервативным и ориентировался на корпоративный сектор, но в 2017 году принял стратегию “Цифровой трансформации” с целью развития направления розничного бизнеса.
Розничный банковский сектор является высококонкурентным в РФ и для реализации стратегии Газпромбанку потребовалось создание новой технологической платформы, которая должна удовлетворять современным требованиям, так как основой интенсивного роста на конкурентном рынке могут быть только data driven процессы.
На тот момент в Банке уже было несколько платформ интеграции данных. Основная платформа КХД занята классическими, но критичными с точки зрения бизнеса задачами: управленческой, финансовой и регуляторной отчетности. Внесение изменения в текущую архитектуру КХД несло серьезные риски и финансовые затраты. Поэтому было принято решение разделить задачи и создавать аналитическую платформу с нуля.
Верхнеуровнево задачи ставились следующие:
- Создание озера данных (как единой среды, в которой располагаются все необходимые для анализа данные);
- Консолидации данных из озера в единую модель;
- Создание аналитический инфраструктуры;
- Интеграция с бизнес-приложениями;
- Создание витрин данных;
- Внедрение Self-service инструментов;
- Создание Data Science окружения.
Бизнес-требования
- Обеспечение данными бизнес-приложений: аналитический CRM, Real Time Offer, Next Best Offer, розничный кредитный конвейер;
- Возможность работы с сырыми данными из систем-источников as is (функция Data Lake);
- Среда статистического моделирования;
- Быстрое подключение новых систем источников к ландшафту;
- Возможность обработки данных за всю историю хранения;
- Единая модель консолидированных данных (аналитическое ядро);
- Графовая аналитика;
- Текстовая аналитика;
- Обеспечение качества данных.
- Высокая производительность при дешевом горизонтальном масштабировании;
- Отказоустойчивость и высокая доступность;
- Разделяемая нагрузка и гарантированный SLA;
- ELT обработка и трансформация данных;
- Совместимость с имеющимися Enterprise решениями (например, SAP Business Objects, SAS);
- Ролевая модель доступа и полное обеспечение требований информационной безопасности.
Для создания единой аналитической платформы розничного бизнеса мы выбрали стек Hadoop на базе дистрибутива Cloudera Data Hub
Архитектура решения
Рассмотрим архитектуру решения.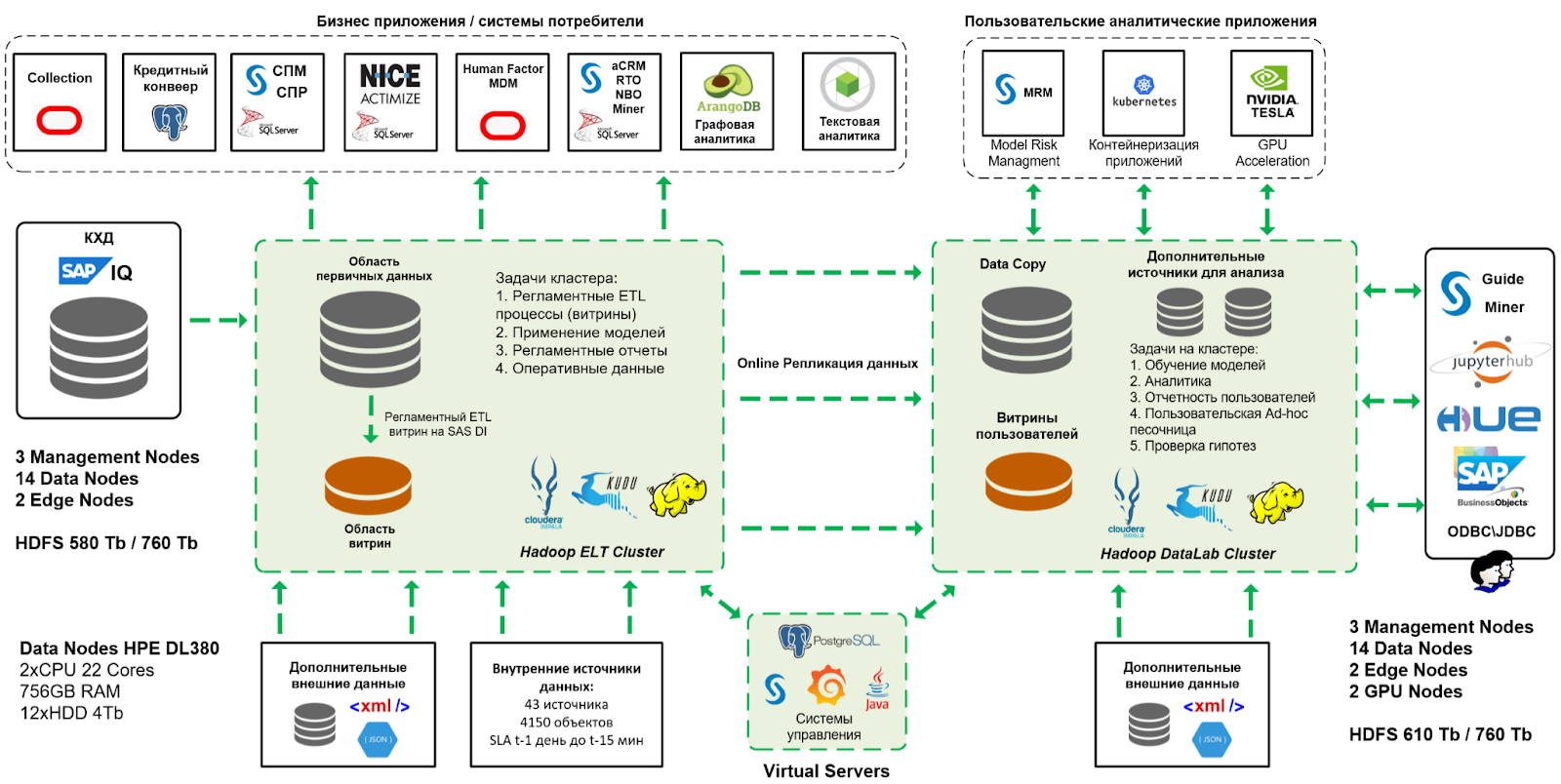
1. Кластер регламентных процессов
Все регламентные источники данных подключаются к данному кластеру. Все регламентные ETL расчеты также работают на этом контуре. Все системы потребители данных “запитываются” из регламентного кластера. Таким образом выполняется жесткая изоляция непредсказуемой пользовательской нагрузки от критичных бизнес процессов.В настоящий момент к Hadoop подключено свыше 40-ка систем-источников с регламентом от t-1 день до t-15 минут для batch загрузки, а также real-time интеграция с процессинговым центром. Регламентный контур поставляет данные во все системы розничного бизнеса:
- Аналитический CRM;
- Розничный кредитный конвейер;
- Антифрод система;
- Система принятия решений;
- Collection;
- MDM;
- Система графовой аналитики;
- Система текстовой аналитики;
- BI отчетность
2. Кластер пользовательских экспериментов “Лаборатория данных”
В то же время, все данные, которые загружаются на регламентный контур в режиме онлайн, реплицируются на контур пользовательских экспериментов. Задержка по времени минимальная и зависит только от пропускной способности сетевого канала тк контур лаборатории данных находится в другом ЦОДе. Те пользовательский контур одновременно выполняет роль Disaster Recovery плеча в случае выхода из строя основного ЦОДа.Дата инженеры и дата science специалисты получают все необходимые данные для проведения своих исследований и проверки гипотез без задержки и без ожидания днями и неделями, когда нужные им данные для расчетов или тренировки моделей, куда-то выгрузят. Они доступны все в одном месте и всегда свежие. Дополнительно на кластере лаборатории данных создаются пользовательские песочницы, где можно создавать и свои объекты. Также ресурсы кластера распределены именно для высококонкурентной пользовательской нагрузки. На регламентный кластер у пользовательского доступа нет.
После проверки гипотез, подготовки требований для регламентных расчетов либо тренировки моделей, результаты передаются для постановки на регламентный контур и сопровождения.
Дополнительно на контуре лаборатории создано окружение управления жизненным циклом моделей, окружение пользовательских аналитических приложений с управлением, ресурсами на K8S, подключены два специализированных узла с GPU ускорением для обучения моделей.
Система мониторинга и управления кластерами, загрузками, ETL, реализована на дополнительных виртуальных машинах, не включенных напрямую в кластера Cloudera.
Сейчас версия дистрибутива CDH 5.16.1. В архитектурный подход закладывалась ситуация выхода из строя двух любых узлов без последующей остановки системы.
Характеристики Data узлов следующие: CPU 2x22 Cores 768Gb RAM SAS HDD 12x4Tb. Все собрано в HPE DL380 в соответствии с рекомендациями Cloudera Enterprise Reference Architecture for Bare Metal Deployments. Такой “необычный”, как кому-то может показаться, сайзинг связан с выбором подхода по ETL и процессингового движка для работы с данными. Об этом немного ниже. Необычность его в том, что вместо “100500” маленьких узлов, мы выбираем меньше узлов, но сами узлы “жирнее”.
Основные технические вызовы
В процессе проработки и внедрения мы столкнулись с рядом технических вызовов, которые необходимо было решить, для того чтобы система удовлетворяла выше заявленным высоким требованиям.- Выбор основного процессингового движка в Hadoop;
- Подход по трансформации данных (ETL);
- Репликация данных «Система-источник –> Hadoop» и «Hadoop –> Hadoop»;
- Изоляция изменений и консистентность данных;
- Управление конкурентной нагрузкой;
- Обеспечение требований информационной безопасности
Выбор основного процессингового движка
Горький опыт первых попыток некоторых игроков реализовать ХД в Hadoop 1.0 показал, что нельзя построить систему обработки данных руками java программистов, не имеющих опыта построения классических ХД за плечами, не понимающих базовых понятий жизненного цикла данных, не способных «отличить дебет от кредита» или «рассчитать просрочку». Следовательно, для успеха нам надо сформировать команду специалистов по данным, понимающих нашу предметную область и использовать язык структурированных запросов SQL.В целом, базовый принцип работы, с данными которого стоит придерживаться – если задачу можно решить на SQL то ее нужно решать только на SQL. А большинство задач с данными решаются именно с помощью языка структурированных запросов. Да и нанять и подготовить команду SQL-щиков для проектной работы быстрее и дешевле чем «специалистов по данным, окончивших курсы на диване из рекламы в инстаграм».
Для нас это означало что необходимо выбрать «правильный» SQL движок для работы с данными в Hadoop. Остановили свой выбор на движке Impala так как он имеет ряд конкурентных преимуществ. Ну и собственно ориентация на Impala во многом и предопределила выбор в пользу Cloudera как дистрибутива Hadoop для построения аналитического хранилища.
Чем же Impala так хороша?
Impala – движок распределенных вычислений, работающий напрямую с данными HDFS, а не транслирующий команды в другой фреймворк вроде MapReduce, TEZ или SPARK.
Impala – движок который большинство всех операций выполняет в памяти.
Impala читает только те блоки Parquet, которые удовлетворяют условиям выборки и соединений (bloom фильтрация, динамическая фильтрация), а не поднимает для обработки весь массив данных. Поэтому в большинстве аналитических задач на практике Impala быстрее, чем другие традиционные MPP движки вроде Teradata или GreenPlum.
Impala имеет хинты, позволяющие очень легко управлять планом запроса, что весьма важный критерий при разработке и оптимизации сложных ETL преобразований без переписывания запроса.
Движок не разделяет общие ресурсы Hadoop с другими сервисами так как не использует YARN и имеет свой ресурсный менеджмент. Это обеспечивает предсказуемую высоко конкурентную нагрузку.
Синтаксис SQL настолько близок к традиционным движкам, что на подготовку разработчика или аналитика, имеющего опыт другой SQL системы, уходит не больше 3-4х часов.
Вот как работа с Hadoop выглядит глазами аналитика:
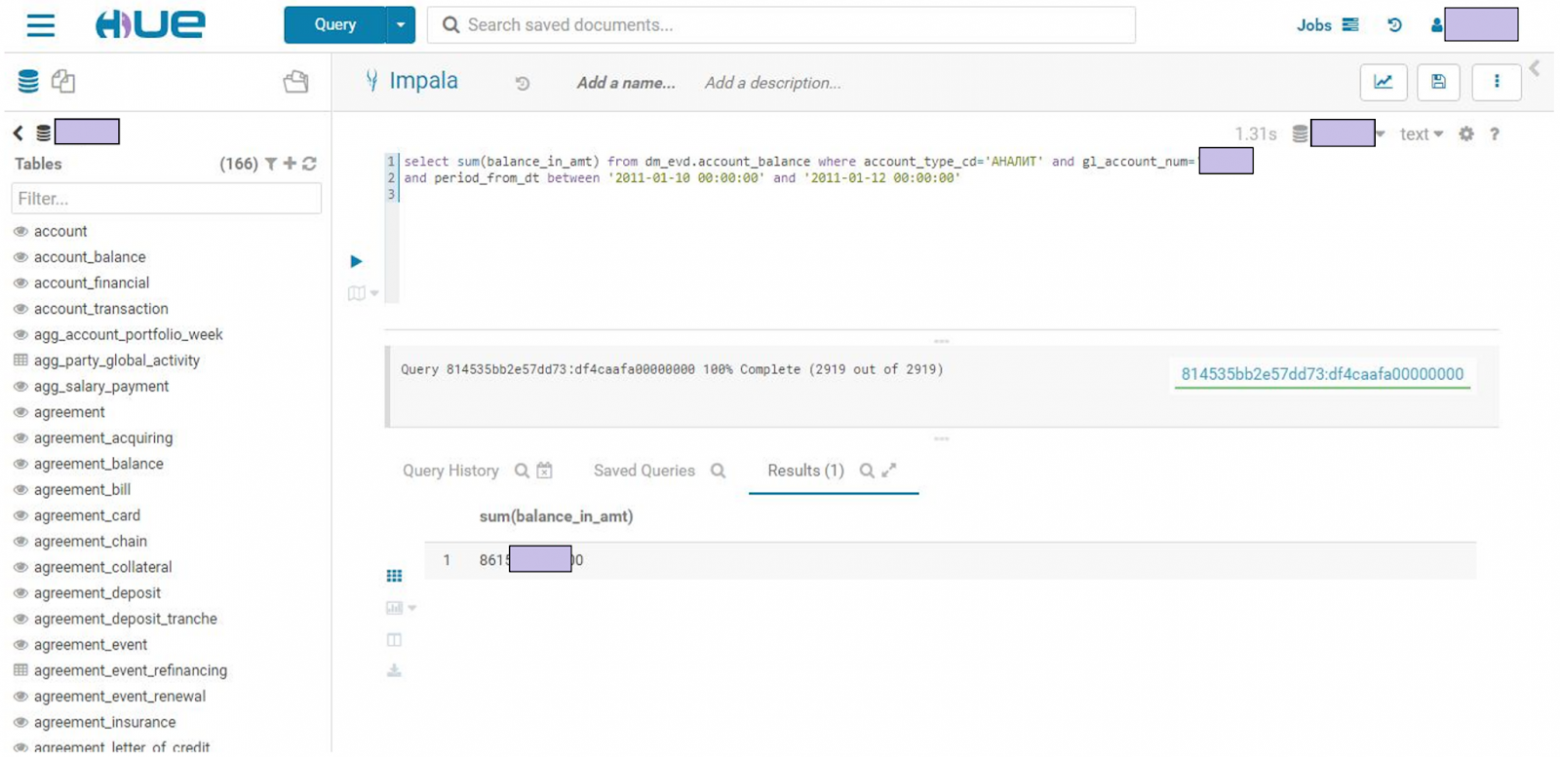
Это проблема легко решаема – ETL поток или запрос в приложении должны уметь перезапускаться в таких ситуациях.
ETL потоки в нашем решении перезапускаются без вмешательства администратора автоматически:
- При падении запроса происходит автоматический анализ причины;
- При необходимости автоматически подбираются параметры конкретного запроса или параметры сессии чтобы повторный перезапуск отработал без ошибок;
- Выполняется сбор статистической информации по ошибкам для дальнейшего анализа и настройки потока чтобы в будущем по данному запросу или job’у таких ситуаций не возникало.
Подход по трансформации данных
В разработке трансформации данных важно не только выбрать правильный движок, но и принять правильные стандарты разработки. У нас давно сформировался подход к таким задачам как metadata driven E-L-T при котором трансформация данных отрисовывается в диаграмме ETL инструмента, который в свою очередь генерирует SQL и запускает его в среде исполнения. При этом SQL должен быть максимально оптимальным с точки зрения конкретной среды исполнения. На рынке не так много ETL инструментов, позволяющих управлять генерацией SQL. В данном внедрении использовался инструмент SAS Data Integration.Весь регламентный ETL выполнен в подходе metadata driven ELT. Никаких ручных скриптов с планировкой на airflow!
Такой подход позволяет
- Автоматизировать процессы управления метаданными;
- Автоматизировать процесс построения lineage данных как средствами самого ETL инструмента, так и средствами доступа к API;
- Повысить качество процессов внесения изменений и управления данными т.к. вся информация о зависимостях всех объектов и всех job’в хранится в метаданных ETL инструмента.
- Использовать CI/CD процессы в разработке
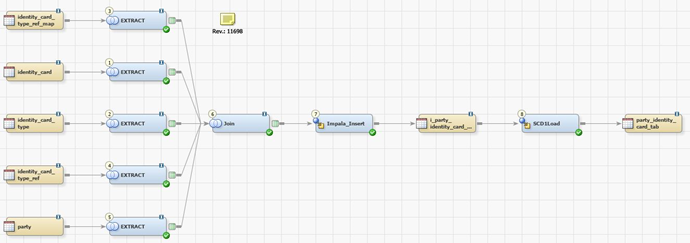
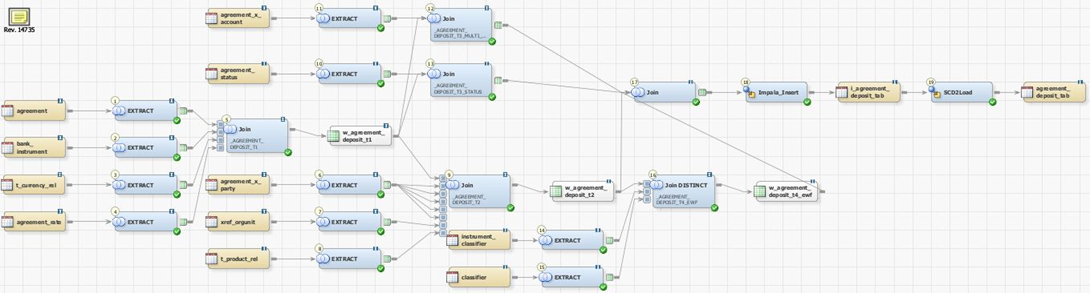
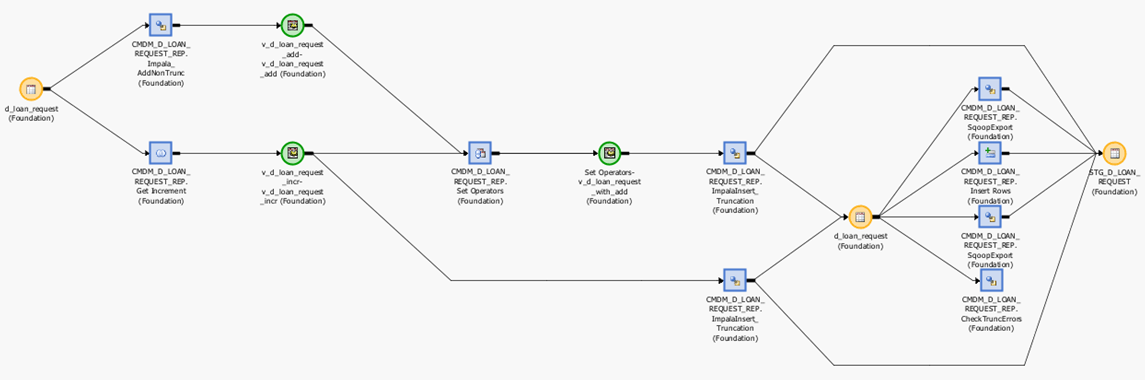
Репликация данных
Загрузка данных в систему – ключевая отправная точка реализации функциональных бизнес требований системы.Для этой функции был разработан специализированный инструмент – Data Replicator. Инструмент позволяет в очень короткие сроки подключать системы источники и настраивать загрузку данных в Hadoop.
Из возможностей
- Синхронизация метаданных с источника;
- Встроенные механизмы контроля качества загруженных данных;
- Загрузка в различных режимах работы в т.ч. полная копия, извлечение и загрузка инкремента (по любой скалярной детерминированной функции), архивация данных источника и т.д.
Другая очень важная функция Data Replicator’а - автоматическая репликация данных с регламентного кластера Hadoop на DR кластер. Данные, загружаемые из систем-источников реплицируются автоматически, для деривативных данных существует API. Все регламентные ETL процессы, при обновлении целевой таблицы вызывают API которое запускает процесс мгновенного копирования изменений на резервный контур. Таким образом, DR кластер, который так же выполняет роль пользовательской песочницы, всегда имеет «свежие» данные.
Нами реализовано множество конфигураций для различных СУБД используемых как источники в ГПБ, также для других процессинговых движков Hadoop (для случаев когда другой кластер Hadoop является источником данных для системы) и есть возможность обрабатывать данные, загруженные в систему другими инструментами, например kafka, flume, или промышленный ETL tool.
Изоляция изменений и консистентность
Любой кто работал в Hadoop сталкивался с проблемой конкурентного доступа к данным. Когда пользователь читает таблицу, а другая сессия пытается туда записать данные, то происходит блокировка таблицы (в случае Hive) либо пользовательский запрос падает (в случае Impala).Самое распространенное решение на практике – выделение регламентных окон на загрузку во время которых не допускается работа пользователей, либо каждая новая порция загрузки записывается в новую партицию. Для нас первый подход неприемлем тк мы должны гарантировать доступность данных 24х7 как по загрузке так и по доступу. Второй подход не применим т.к. он предполагает секционирование данных только по дате\порции загрузке, что неприемлемо если требуется отличное секционирование (по первичному ключу, по системе источнику и т.д.). Так же второй метод приводит к избыточному хранению данных.

В нашем решении изоляция выполнена с применением подхода HDFS snapshot и разделения слоя хранения и доступа к данным через VIEW.
Когда данные записываются в HDFS, сразу, мгновенно создается снапшот на который переключается VIEW.
Пользователь читает данные с VIEW, а не напрямую с таблицы, поэтому следующая сессия записи никак не влияет на его текущий запрос.
Все что остается делать – это переключать VIEW на новые HDFS снапшоты, число которых определяется максимальной длительностью пользовательских запросов и частотой обновления данных в Hadoop. Те в сухом остатке мы получаем аналог UNDO в Oracle, retention период которого зависит от количества снапшотов и регламента загрузки данных.
Основной секрет в том, что как только процессинговый движок определил какие данные из HDFS он должен прочитать, после этого DDL VIEW или таблицы может быть изменен т.к. оптимизатор больше не будет обращаться к словарю metastore. Т.е. можно выполнить переключение VIEW на другую директорию.
Функционал HDFS Snapshot настолько легковесный и быстрый что позволяет создавать сотни снапшотов в минуту и никак не влияет на производительность системы.
Изоляции изменений в нашем решении также является функцией DataReplictor’а. Все загружаемые данные изолируются автоматически, причем на обеих контурах системы, а производные ETL данные изолируются через вызов API. Каждое изменение целевого объекта, которое происходит в рамках ETL процесса завершается вызовом API по созданию снапшота и переключению VIEW.
Благодаря такому решению, все загрузки и все данные доступны в режиме 24х7 без регламентных окон. HDFS снапшоты не приводят к большому избыточному хранению данных в HDFS. Наш опыт показал, что для часто меняющихся регламентных данных хранение снапшотов за трое суток приводит к увеличению размера максимум на 25%.
Управление конкурентной нагрузкой
Следующий большой блок требований – управление конкурентной нагрузкой.На практике это означает что нужно обеспечить
- Предсказуемую работу регламентных процессов;
- Приоритизация пользователей в зависимости от принадлежности к ресурсной группе;
- Отсутствие, минимизация или управление отказами в обслуживании;
- Настроено разделение ресурсов между сервисами Hadoop на уровне ОС через cgroups;
- Правильное распределение памяти между нуждами ОС и Hadoop;
- Правильное распределение памяти внутри кластера между служебными сервисами Hadoop, YARN приложениями и Impala;
- Выделение ресурсных пулов Impala отдельным пользовательским группам – для гарантии обслуживания и приоритизации запросов.
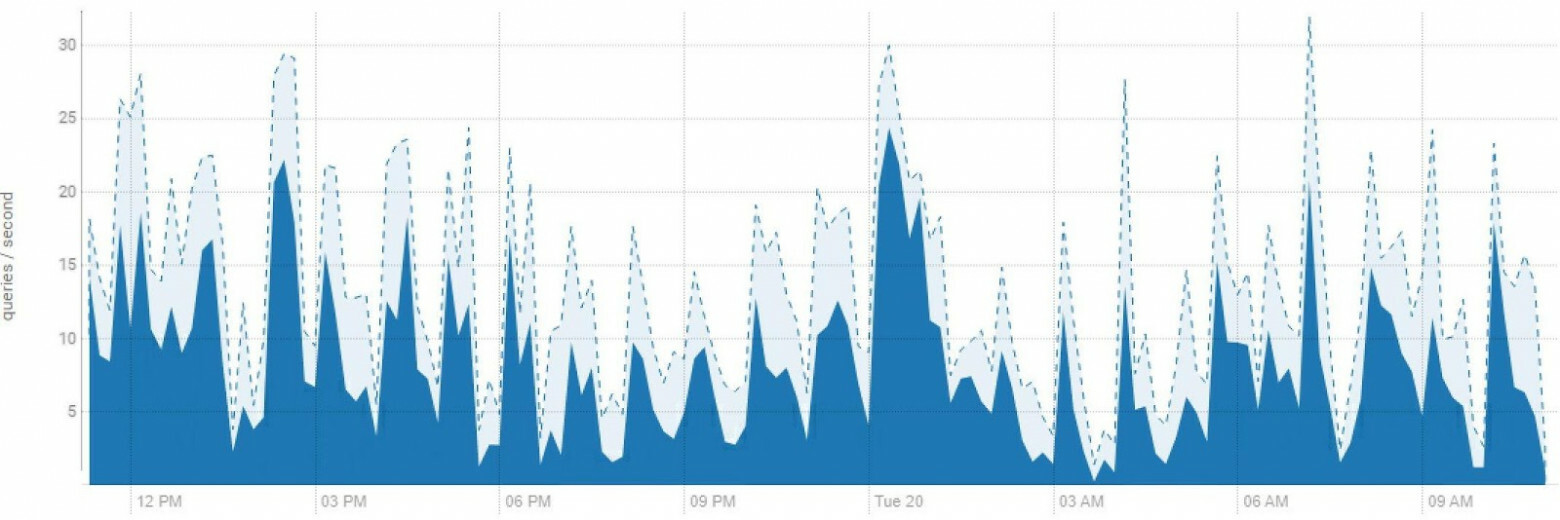
В настоящий момент на кластере регламентных расчетов в сутки регистрируется и успешно выполняется в среднем 900 тыс SQL запросов по трансформации и загрузке данных. В дни массовых загрузок и расчетов эта цифра поднимается до полутора миллионов.

Информационная безопасность
В финансовом секторе традиционно вопросы информационной безопасности являются одними из самых ключевых тк приходится работать с данными, которые не только подлежат защите с тз федерального законодательства, но и с требованиями, которые периодически ужесточаются госрегулятором. При выборе дистрибутива Hadoop стоит особое внимание уделять этим требованиям, так как большинство не вендорских сборок, либо сборок, спроектированных на базе популярных open source дистрибутивов (например Apache Big Top) не позволяют закрывать часть требований и при выводе системы в промышленную эксплуатацию можно столкнуться с неприятными сюрпризами недопуска системы от службы ИБ.В кластере Cloudera нами были реализованные следующие требования:
- Ролевая модель доступа к данным
- Все пользователи включены в группы Active Directory (AD) каталога;
- Группы AD зарегистрированы в Sentry;
- В Sentry выполнено разграничение доступа для баз Impala и директорий HDFS;
- Каждый Target слой данных имеет ролевые слои VIEW с ограничениями на чувствительные данные в соответствии с ролевой моделью доступа;
- Кластеры керберизированы;
- Подключение клиентских приложений только с применением SSL шифрования. Также шифрование используется при передачи данных внутри кластера.
- Выполняется парсинг и приведение всех журналов сервисов Hadoop к единому реляционному формату стандартного журнала ИБ (единая точка интеграции для системы сбора данных ИБ)
- Пользовательские запросы;
- Запросы ETL;
- Точки интеграции Hadoop с другими системами;
- Все серверы, ОС, компоненты и прикладное ПО настроены в соответствии с согласованными профилями информационной безопасности и периодически проходят проверку на предмет известных уязвимостей.
Единый аналитический слой данных
Наличие общего слоя консолидированных данных – основное требование аналитического ХД.Без этого Hadoop (как и любое другое ХД) – озеро данных, которое пользователи начинают превращать со временем в неуправляемое болото. Поэтому важно иметь общую версию правды над этим озером чтобы все задачи решались в единой системе координат.
Был разработан единый аналитический слой консолидированных данных. Источником для него является копия детального слой КХД, которая регулярно реплицируется в среду Hadoop, а также дополнительные источники, подключаемые напрямую, минуя КХД.
Модель ориентирована на пользовательский ad-hoc доступ и проектировалась с учетом требований типовых задач клиентской аналитики, риск моделей, скоринга.
Реализованы все области данных, необходимые для решения задач розничного бизнеса и моделирования такие как:
- Аккредитивы;
- Депозиты;
- Залоги;
- Заявки;
- Карты;
- Контрагенты;
- MDM;
- Кредиты;
- Сегмент клиента;
- Рейтинги;
- Агрегаты;
- Справочники;
- Счета;
- Эквайринг;
- Векселя;
- РЕПО;
- Резервы.
В модель загружена история с 2010 года. Ведь точность моделей зависит от глубины истории данных, на которых она обучается. Более того, история очищалась аналитическими алгоритмами. В банке разветвленная филиальная сеть и часть филиалов мигрировали друг в друга, клиенты переходили из одного филиала в другой, производили пролонгацию сделок и тд. Все это составляет определенные сложности для анализа данных. Но в конечном целевом слое вся история отношений с каждым клиентом, все сделки, имеют непрерывную историю в рамках одного суррогатного ключа без пересекающихся интервалов историчности.
Реализованный единый слой - источник данных для производных прикладных витрин под бизнес-приложения, отчетность и модели. Сейчас у нас около 40 производных регламентных витрин, состоящих из 550 целевых таблиц и примерно 13200 атрибутов.
Надежность
Часто приходится слушать о ненадежности решений, спроектированных на Hadoop. За два года эксплуатации Cloudera Data Hub у нас практически не было каких-либо проблем, связанных с простоем системы. Случилось буквально пара инцидентов, повлиявших не регламентные процессы.Один раз у нас забилось место, выделенное под БД metastore (недостатки мониторинга).
В другой раз была попытка выгрузить несколько сотен миллионов транзакций через Impala. В результате “прилег” координатор и другие пользователи и процессы не могли подключиться на этот координатор. Как результат выработали правило – каждый отдельный вид процессов (загрузка данных, ETL, пользователи, приложения) подключается к своему координатору, который еще имеет дублера для балансировки. Ну и конечно большие выгрузки данных в системы потребители лучше делать через sqoop export. Ну и в последних релизах Impala уже без проблем может отдавать десятки миллионов записей на подключение.
Да, случаются выходы из строя дисков, приходится иногда делать decommission узлов для их замены, но все это проходит прозрачно для пользователей без остановки работы, ведь наш архитектурный подход сразу подразумевал устойчивость к выходу из строя как минимум двух любых узлов.
Итоги
В настоящий момент система является фабрикой данных всех розничных процессов Банка и аналитических приложений. Платформой ежедневно пользуется 36 департаментов и примерно 500 пользователей для самостоятельного решения задач по аналитике и моделированию.
Выводы
После двух лет промышленной эксплуатации нашей Системы мы сегодня с уверенностью можем сказать, то экосистема Hadoop полностью позволяет реализовать все современные требования к аналитической платформе при использовании дистрибутива Cloudera и при правильных архитектурных подходах. Система может полностью вытеснить все традиционные аналитические СУБД без какого-либо ущерба к накопленному опыту разработчиков и аналитиков. Нужно всего лишь принять правильные решения и сделать “прыжок веры”. Традиционно консервативный Газпромбанк сделал с нами этот “прыжок веры” и смог построить современную аналитическую платформу, ввязавшись в гонку на розничном рынке в кратчайшие сроки.Об успехах в цифрах можно посмотреть в записи нашего совместно доклада.
Для проектирования современной аналитической системы не требуется гетерогенная архитектура слоеного пирога с пропитками из “гринпламов”, “тарантулов”, “игнайтов” и так далее. Все данные и сервисы работы с данными должны находится под управлением одной целостной системы. Такой подход снижает наличие дополнительных точек интеграции, а следовательно, и потенциальные отказы. Не требуются дополнительные работы и длительные сроки по интеграции и «пропитке» этих слоев данными.
Наш архитектурный подход позволяет ускорить внедрение нового функционала и как следствие улучшить time to market новых продуктов, основанных на data driven процессах.
В современных аналитических задачах не существует понятий горячих и холодных данных. Ситуация “прилета” пачки проводок, за диапазон t - 3-5 лет - это каждодневная регламентная ситуация. И для такого случая вы должны пересчитать остатки, обороты, просрочки и предоставить данные для модели или определения сегмента клиента в аналитическом CRM. Как я уже писал выше, чем глубже в истории данные, тем точнее ваши модели. Такие задачи можно решить только если все данные в одном месте и в одной системе. Наш принцип - все данные горячие!
Для успешной реализации проектной команде недостаточно опыта знания технологии Hadoop. Hadoop это всего лишь инструмент. Необходимо применять подходы проектирования классического ХД на базе SQL MPP, иначе ваша система навсегда останется “помойкой” под архивные данные, нарисованной внизу слоеного пирога как “хранилище неструктурированных и холодных данных” на архитектурной картинке.
Наши ближайшие планы
В настоящий момент мы находимся в завершающей стадии миграции на новую платформу Cloudera Data Platform 7.1. Вполне вероятно, что на момент публикации мы уже на CDP и в ближайшее время тут будут опубликованы результаты. Пока, можно с уверенностью сказать, что после проведенных тестов, мы ожидаем ряд оптимизационных улучшений, связанных с Impala 3.4, появлением страничных индексов в parquet, наличием Zstd компрессии. Новые сервисы вроде Atlas и Cloudera Data Flow позволят закрывать функции управления данными и потоковой аналитики «из коробки». В ближашее время мы также планируем пилотировать родной для Cloudera BI инструмент - Cloudera Data Visualization.Что еще мы сделали в нашем ландшафте Hadoop:
- Real-time интеграция системы с процессинговым центром с использованием Kudu (real-time клиентские данные, доступные для работы с минимальной задержкой наступления события). Горячие данные в Kudu, холодные в Parquet, общий «склеивающий» интерфейс доступа для пользователей через SQL Impala. Результат - данные в реальном времени о состоянии карточных транзакций и остатков по карточному счету открывают для бизнеса новые возможности.
- Историзируемый слой ODS
- Графовая аналитика
- Построение витрины property графа в Hadoop;
- Загрузка в графовую БД Arango;
- Интерфейс работы с графом для андерайтеров над Arango;
- Графовые модели (анализ окружения клиента при скоринге);
- Текстовая аналитика
- Работа моделей по распознаванию первичных документов клиента и поиска в них аномалий (контроль фронта, антифрод, автоматизация работы с заявкой);
- Анализ новостных лент, тематических форумов
- Геоаналитика
- Анализ удаленности и проходимости офисов от основных пешеходных маршрутов, автомобильных проездов и парковок;
- Оптимизация курьерских маршрутов
- Система управления качеством данных, позволяющая оценить качество всех загружаемых и производных данных для принятия решений об использовании этих данных на прикладном уровне. Результат - мониторинг через визуальные дашборды и почтовые рассылки состояния качества данных аналитического слоя, поставка данных в системы потребители вместе с “паспортом качества”.
- Контейнеризация пользовательских приложений и моделей с использованием окружения K8S
Авторы:
Евгений Вилков, ГлоуБайт.
Колесникова Елена, Газпромбанк (АО).