
- сбор телеметрии с промышленных датчиков по протоколу Modbus;
- их передачу в облако;
- локальный мониторинг процесса в реальном времени.
Настало время это исправить - разберемся с тем, как можно накапливать и обрабатывать переданную телеметрию в Яндекс Облаке.
Требуемый функционал
В рамках нашего решения облако должно решать следующие основные задачи:
- принимать телеметрию устройства;
- накапливать телеметрию в хранилище;
- предоставлять доступ к накопленным данным с целью их последующего использования при разработки моделей, формирования отчетов и пр.
Доступные инструменты
Сбор и обработка телеметрии
Yandex IoT Core
В первой части мы уже познакомились с Yandex IoT Core и достаточно подробно разобрали его функционал. Если кратко, это MQTT-брокер от Яндекса, с помощью которого осуществляется обмен сообщениями между реестрами и устройствами.
Его мы и используем, чтобы отправлять телеметрию устройства в облако (как именно? велком в первую часть)
Yandex Cloud Functions
По умолчанию, с полученными по MQTT сообщениями в облаке ничего не происходит и информацию о них можно увидеть только в логах реестра или устройства. Для того, чтобы обработать присланную телеметрию нужно использовать сервис Yandex Cloud Functions.
Этот сервис позволяет разворачивать serverless-функции (на данный момент на Python, Node.js, Bash, Go и PHP), а также обладает механизмом “триггеров” - запуска развернутых функций по какому-либо условию (таймеру, событию).
Например, можно создать функцию-обработчик сообщения телеметрии и триггер, привязанный к топику устройства или реестра IoT Core, который будет отправлять пришедшие в топик сообщения на обработку этой функции. Таким образом, способы обработки сообщений ограничивается только возможностями выбранного языка программирования, квотами и лимитами сервиса.
Yandex Message Queue
Yandex Message Queue - сервис для обмена сообщениями между приложениями. В рамках этого сервиса можно реализовать механизм очередей, в которые одни приложения отправляют сообщения, а другие - забирают.
Этот механизм будет полезен, если в качестве хранилища использовать ClickHouse или схожие аналитические колоночные СУБД, плохо переносящие единичные вставки - в очереди можно накопить пачку сообщений и отправить их на вставку одним большим пакетом.
Хранение телеметрии
Для хранения данных Яндекс Облако предоставляет большое количество Managed Services для разных СУБД.
Managed Service любой СУБД, позволяет быстро развернуть готовый к работе кластер с необходимым хранилищем. Также в рамках облака можно быстро масштабировать ресурсы кластера в случае увеличения нагрузки.
Доступные на текущий момент СУБД:
- PostgreSQL
- ClickHouse
- MongoDB
- MySQL
- Redis
- SQL Server
Использование накопленной телеметрии
Yandex DataLens
Это сервис визуализации данных и анализа данных. Позволяет достаточно быстро создавать дашборды на основе данных из разнообразных источников.
Можно подключаться как к хранилищам, развернутым в облаке, так и сторонним источникам.
Yandex DataSphere
Сервис для ML-разработки, предоставляющий все необходимые инструменты и динамически масштабируемые ресурсы для полного цикла разработки машинного обучения.
Работа ведется в ноутбуках JupyterLab, есть возможность выбора ресурсов, на которых будет выполняться каждая отдельная ячейка (количество ядер, GPU).
Дополнительные инструменты
Yandex Monitoring
Сервис позволяет собирать, хранить и отображать метрики облачных ресурсов, а также настраивать алерты и присылать по ним уведомления. В отличии от DataLens, умеет обновлять графики онлайн и подходит для мониторинга в реальном времени!
Настройка сохранения телеметрии
Несмотря на разнообразие инструментов, сейчас мы ограничимся тем, что будем просто сохранять телеметрию, пришедшую в IoT Core, в базу данных.
Для этого нам нужно развернуть и настроить 4 элемента:
- IoT Core: создать реестр, устройство, наладить передачу сообщений по MQTT (сделано в первой части);
- Managed Service for PostgreSQL - развернуть кластер, создать таблицу для хранения телеметрии;
- Cloud Functions - написать функцию-обработчик сообщения с телеметрией: функция должна записывать payload сообщения в БД;
- Cloud Functions - настроить триггер IoT Core, который будет запускать функцию-обработчик при появлении нового сообщения в топике реестра.
Настройка PostgreSQL
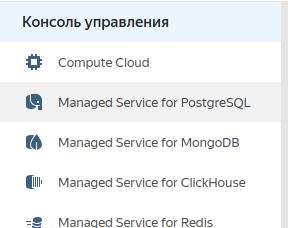
Для начала подключаем и настраиваем кластер Postgres:
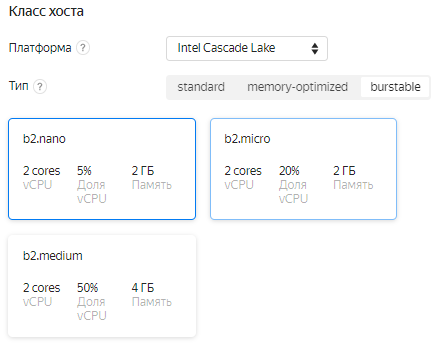
Нам подойдет самая минимальная конфигурация - b2.nano (если впоследствии проект перерастет во что-то большее, ее легко можно будет расширить):
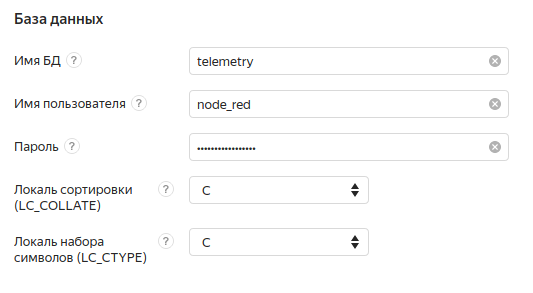
Создадим кластер. Теперь придется подождать некоторое время пока кластер развернется и его статус поменяется с Creating на Alive.


Создание функции-обработчика
Функция будет получать сообщения из MQTT-брокера и записывать данные в таблицу, созданную ранее.
В каталоге в консоли выбираем Cloud Functions:

В открывшемся редакторе выбираем среду выполнения. Мы будем использовать Python 3.7 (preview).
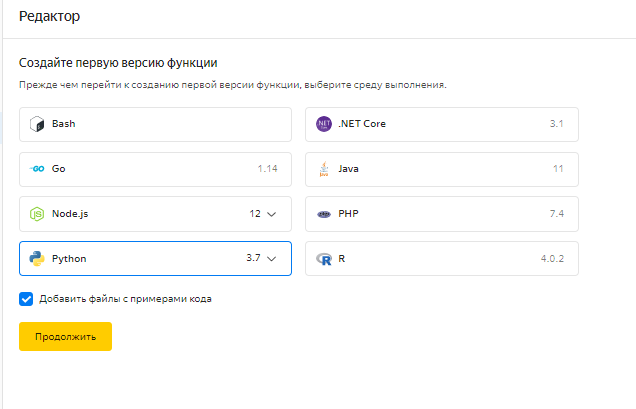
Мы будем использовать код, предоставленный в документации Яндекс Облака (гитхаб), немного поправив его под наши нужды.
Правки касаются формата таблицы и payload сообщений:
- Функция makeInsertStatement:
- Поменяем формат инсерта согласно формату нашей таблицы, уберем разбор пэйлоада на отдельные поля, а также изменим входную переменную event_id на event_ts.

- Функция makeCreateTableStatement:
- Изменим выражение в соответсвтии с форматом таблицы.
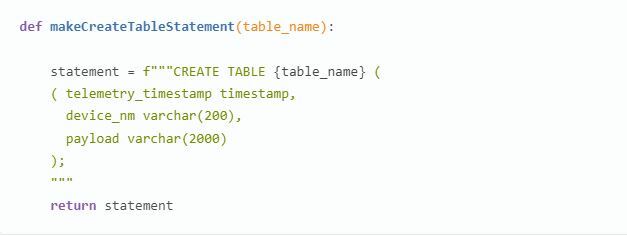
Функция msgHandler:
- Изменим переменную event_id на event_ts (96 строка) и будем формировать ее следующим образом:



Код с уже внесенными правками можно найти в этом гисте. Вставим его в файл index.py.
Обратите внимание, если вы использовали другое название таблицы для сохранения телеметрии, необходимо указать его в качестве значения переменной table_name на 79 строке.
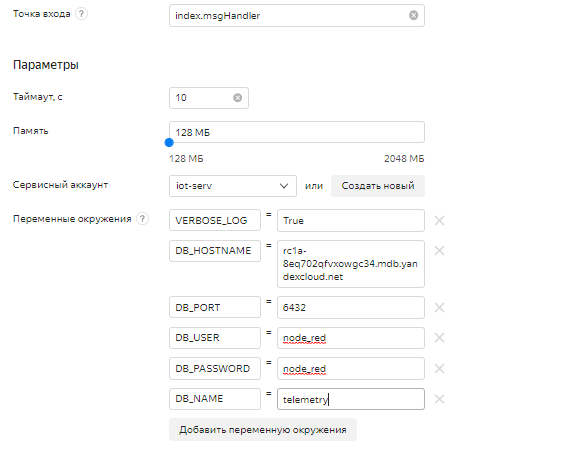
Теперь, перед созданием версии функции, в форме под редактором необходимо заполнить параметры развертывания:
- Точка входа: укажем index.msgHandler - это имя функции в файле index.py, которая будет вызываться в качестве обработчика. Указывается в формате <имя файла с функцией>.<имя обработчика>
- Таймаут, с: 10 секунд -максимальное время выполнения функции. Облачная функция может выполняться не более 10 минут.
- Память: 128 МБ - объем необходимой для функции памяти
- Сервисный аккаунт - укажем (или создадим, если его еще нет) сервисный аккаунт с ролями serverless.functions.invoker и editor
- Переменные окружения - обратите внимание, разработанная функция использует 6 переменных окружения, которые необходимо заполнить в соответствующих полях. Нужно указать следующее:
- VERBOSE_LOG — параметр, отвечающий за вывод подробной информации о выполнении функции. Введем значение True.
- DB_HOSTNAME — имя хоста БД PostgreSQL для подключения.
- DB_PORT — порт для подключения.
- DB_NAME — имя базы данных для подключения.
- DB_USER — имя пользователя для подключения.
- DB_PASSWORD — пароль, который был введен при создании кластера
Все данные для подключения (кроме пароля) можно найти в обзоре развернутого Managed Service for PostgreSQL.
В итоге мы получаем такое заполнение полей:
Настройка триггера IoT Core
Вернемся в раздел Cloud Functions и выберем подраздел “Триггеры”.
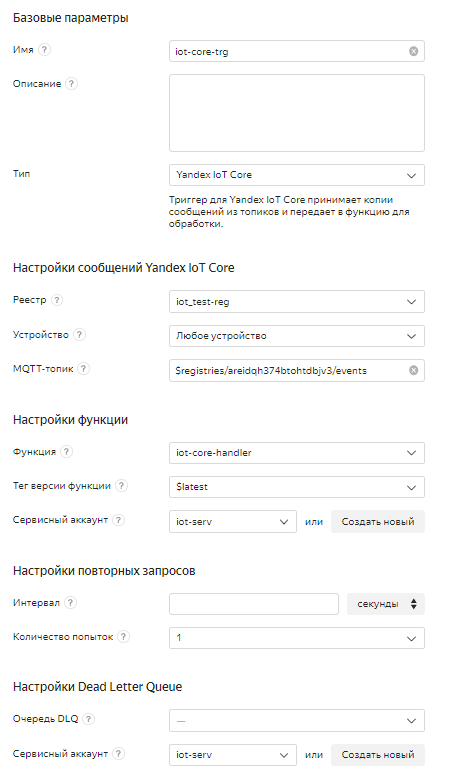
- В блоке Базовые параметры:
- В поле Имя введем имя триггера.
- В поле Тип выберем Yandex IoT Core. Так мы укажем сервису, что будем работать с обработкой событий IoT Core. Кроме этого источника, для решения других задач можно обрабатывать сообщения Message Queue, события Object Storage, Container Registry, логов Cloud Logs, а также запускать функцию по таймеру.
- В блоке Настройки сообщений Yandex IoT Core:
- В поле Реестр введем iot_test-reg - реестр к которому привязано наше устройствою
- В поле Устройство выберем Любое устройство (т.к. мы отправляем сообщения в топик реестра)
- В поле Топик укажем топик, в который устройство отправляет данные:
- $registries/<ID реестра>/events
- В блоке Настройки функции:
- Выберем функцию для обработки данных, созданную ранее (iot-core-handler).
- В поле Тег версии укажем $latest - тогда триггер будет запускать последнюю развернутую .
- В поле Сервисный аккаунт укажем созданный ранее сервисный аккаунт.
- Остальные поля оставим пустыми.
Проверка работоспособности
Всё готово!
Теперь (если всё сделано правильно) каждое сообщение, отправляемое устройством, будет через созданный триггер инициировать вызов функции. Которая, в свою очередь, положит отправленный payload в таблицу на Postgres.
Проверим логи выполнения функции (Cloud Functions -> Функции -> iot-core-handler -> Логи).
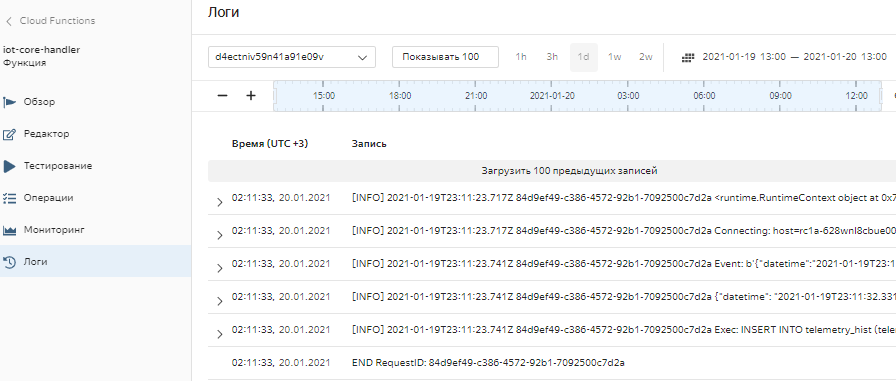
Здесь отображаются сообщения, выводимые функцией в процессе работы, в том числе, сообщения об ошибках. Если сообщений об ошибках нет (а есть информационные сообщения, начинающиеся с [INFO]) - функция работает корректно.
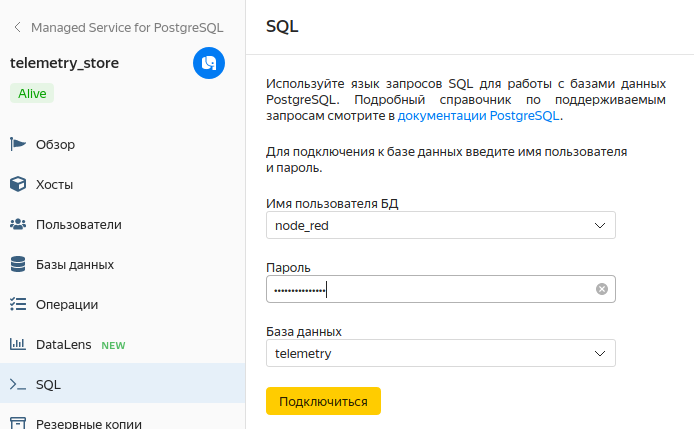
Посмотрим теперь заполнение таблицы telemetry_hist в нашей БД (Managed Services for PostgresSQL -> telemetry_store -> SQL). Вводим имя пользователя и пароль и попадаем в редактор SQL.
Вводим простой запрос для получения выгрузки из таблицы

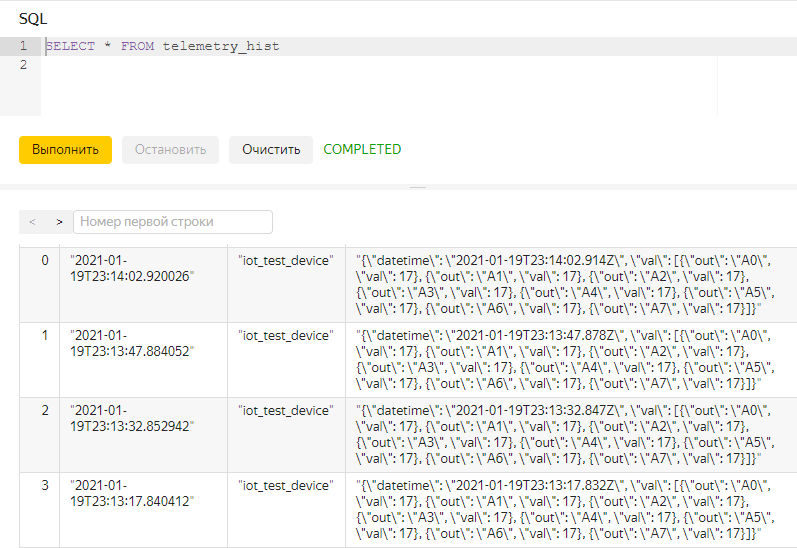
То есть всё работает: теперь телеметрия попадает в облако, накапливается в развернутой БД и доступна для дальнейшего анализа в любое удобное время из любой точки планеты!
PS. Если по каким-то причинам таблица остается пустой, можно проверить следующие моменты:
Отправило ли устройство хотя бы одно сообщение с момента деплоя функции и триггера?
- Если нет - просто ждем пока это произойдет)
- Если отправляло - смотрим логи выполнения функции.
- Если логи пустые - стоит проверить триггер (в частности правильно ли указан топик и функция).
- Если в логах ошибки - разбираемся с кодом.
- Если функция отрабатывает и ошибок нет - проверяем настройки подключения к БД и имя таблицы.